拨开字符编码的迷雾
为什么有些软件界面上的韩文会显示乱码?
ASCII 和 ANSI 有什么区别?
相信不少人在字符编码上面摔过跟头,这篇文章针对开发中需要了解的字符编码知识进行讲解,希望帮助大家拨开字符编码的迷雾,从此告别乱码的困扰。
ASCII 及其扩展
什么是 ASCII 字符集
字符集就是一系列用于显示的字符的集合。
ASCII 字符集由美国国家标准协会(American National Standard Institute)于 1968 年制定一个字符映射集合。
ASCII 使用 7 位二进制位来表示一个字符,总共可以表示 128 个字符(即2^7,二进制000 0000 ~ 111 1111,十进制0~127)。
ASCII 字符集中每个数字对应一个唯一的字符,如下表:
| ASCII | Hex | 字符 | ASCII | Hex | 字符 | ASCII | Hex | 字符 | ASCII | Hex | 字符 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0x00 | NUL | 1 | 0x01 | SOH | 2 | 0x02 | STX | 3 | 0x03 | ETX |
| 4 | 0x04 | EOT | 5 | 0x05 | ENQ | 6 | 0x06 | ACK | 7 | 0x07 | BEL |
| 8 | 0x08 | BS | 9 | 0x09 | HT | 10 | 0x0A | LF | 11 | 0x0B | VT |
| 12 | 0x0C | FF | 13 | 0x0D | CR | 14 | 0x0E | SO | 15 | 0x0F | SI |
| 16 | 0x10 | DLE | 17 | 0x11 | DC1 | 18 | 0x12 | DC2 | 19 | 0x13 | DC3 |
| 20 | 0x14 | DC4 | 21 | 0x15 | NAK | 22 | 0x16 | SYN | 23 | 0x17 | ETB |
| 24 | 0x18 | CAN | 25 | 0x19 | EM | 26 | 0x1A | SUB | 27 | 0x1B | ESC |
| 28 | 0x1C | FS | 29 | 0x1D | GS | 30 | 0x1E | RS | 31 | 0x1F | US |
| 32 | 0x20 | Space | 33 | 0x21 | ! | 34 | 0x22 | “ | 35 | 0x23 | # |
| 36 | 0x24 | $ | 37 | 0x25 | % | 38 | 0x26 | & | 39 | 0x27 | ‘ |
| 40 | 0x28 | ( | 41 | 0x29 | ) | 42 | 0x2A | * | 43 | 0x2B | + |
| 44 | 0x2C | , | 45 | 0x2D | - | 46 | 0x2E | . | 47 | 0x2F | / |
| 48 | 0x30 | 0 | 49 | 0x31 | 1 | 50 | 0x32 | 2 | 51 | 0x33 | 3 |
| 52 | 0x34 | 4 | 53 | 0x35 | 5 | 54 | 0x36 | 6 | 55 | 0x37 | 7 |
| 56 | 0x38 | 8 | 57 | 0x39 | 9 | 58 | 0x3A | : | 59 | 0x3B | ; |
| 60 | 0x3C | < | 61 | 0x3D | = | 62 | 0x3E | > | 63 | 0x3F | ? |
| 64 | 0x40 | @ | 65 | 0x41 | A | 66 | 0x42 | B | 67 | 0x43 | C |
| 68 | 0x44 | D | 69 | 0x45 | E | 70 | 0x46 | F | 71 | 0x47 | G |
| 72 | 0x48 | H | 73 | 0x49 | I | 74 | 0x4A | J | 75 | 0x4B | K |
| 76 | 0x4C | L | 77 | 0x4D | M | 78 | 0x4E | N | 79 | 0x4F | O |
| 80 | 0x50 | P | 81 | 0x51 | Q | 82 | 0x52 | R | 83 | 0x53 | S |
| 84 | 0x54 | T | 85 | 0x55 | U | 86 | 0x56 | V | 87 | 0x57 | W |
| 88 | 0x58 | X | 89 | 0x59 | Y | 90 | 0x5A | Z | 91 | 0x5B | [ |
| 92 | 0x5C | \ | 93 | 0x5D | ] | 94 | 0x5E | ^ | 95 | 0x5F | _ |
| 96 | 0x60 | ` | 97 | 0x61 | a | 98 | 0x62 | b | 99 | 0x63 | c |
| 100 | 0x64 | d | 101 | 0x65 | e | 102 | 0x66 | f | 103 | 0x67 | g |
| 104 | 0x68 | h | 105 | 0x69 | i | 106 | 0x6A | j | 107 | 0x6B | k |
| 108 | 0x6C | l | 109 | 0x6D | m | 110 | 0x6E | n | 111 | 0x6F | o |
| 112 | 0x70 | p | 113 | 0x71 | q | 114 | 0x72 | r | 115 | 0x73 | s |
| 116 | 0x74 | t | 117 | 0x75 | u | 118 | 0x76 | v | 119 | 0x77 | w |
| 120 | 0x78 | x | 121 | 0x79 | y | 122 | 0x7A | z | 123 | 0x7B | { |
| 124 | 0x7C | | | 125 | 0x7D | } | 126 | 0x7E | ~ | 127 | 0x7F | DEL |
因为其对应关系非常简单,不需要特殊的编码规则,所以严格来讲 ASCII 不能算字符编码,因为它没有规定编码规则。我们只是习惯性的将 ASCII 字符集称之为 ASCII 码、ASCII 编码。
ASCII 的扩展
扩展最高位
ASCII 字符集是美国人发明的,其中的字符完全是为其自己量身定制的。随着计算机技术普及到欧洲(如法国、德国)各国,欧洲很多国家使用的字符除了 ASCII 表中的 128 个字符之外,此时欧洲人民发现 ASCII 字符集不能完全表达他们所要表达的内容。
<原文出自: jiangxueqiao.com,请尊重原创>
怎么办了?他们发现 ASCII 只使用了一个字节(8 位)之中的低 7 位,于是欧洲各国开始各显神通,打起了最高位(第 0 位)的主意,将最高位利用了起来,这样又多了 128 个字符,从而满足了欧洲人民的需要。
但因为每个国家的需求不一样,各国都设计了不同的方案。为了结束这种混乱的局面,国际标准化组织(ISO)及国际电工委员会(IEC)联合制定了一系列 8 位字符集的标准,统称为 ISO 8859(全称 ISO/IEC 8859)。注意,这是一系列字符集的统称,如 ISO/IEC 8859-1(也就是常听到的 Latin-1)支持西欧语言,ISO/IEC 8859-4(Latin-4)支持北欧语言等。
完整列表如下(摘自百度百科):
ISO/IEC 8859-1 (Latin-1) - 西欧语言
ISO/IEC 8859-2 (Latin-2) - 中欧语言
ISO/IEC 8859-3 (Latin-3) - 南欧语言,世界语也可用此字符集显示。
ISO/IEC 8859-4 (Latin-4) - 北欧语言
ISO/IEC 8859-5 (Cyrillic) - 斯拉夫语言
ISO/IEC 8859-6 (Arabic) - 阿拉伯语
ISO/IEC 8859-7 (Greek) - 希腊语
ISO/IEC 8859-8 (Hebrew) - 希伯来语(视觉顺序)
ISO 8859-8-I - 希伯来语(逻辑顺序)
ISO/IEC 8859-9 (Latin-5 或 Turkish) - 它把 Latin-1 的冰岛语字母换走,加入土耳其语字母。
ISO/IEC 8859-10 (Latin-6 或 Nordic) - 北日耳曼语支,用来代替 Latin-4。
ISO/IEC 8859-11 (Thai) - 泰语,从泰国的 TIS620 标准字集演化而来。
ISO/IEC 8859-13 (Latin-7 或 Baltic Rim) - 波罗的语族
ISO/IEC 8859-14 (Latin-8 或 Celtic) - 凯尔特语族
ISO/IEC 8859-15 (Latin-9) - 西欧语言,加入 Latin-1 欠缺的芬兰语字母和大写法语重音字母,以及欧元符号。
ISO/IEC 8859-16 (Latin-10) - 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号。
我们在数据库或 Qt 中常见到的 Latin-1、2、5、7 其实就是上面提到的针对特定语言的 ASCII 扩展字符集。
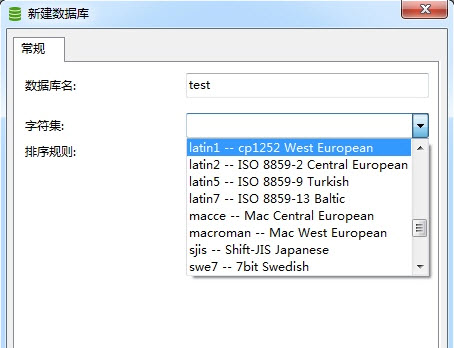
多字节扩展 - GB 系列
前面讲到了,欧洲各国有效利用闲置的最高位对 ASCII 字符集进行了扩展。可是欧洲人民没有想到在大洋彼岸有着一个拥有五千年历史的伟大民族,她拥有着成千上万的汉字,1 个字节显然不够表达如此深厚的文化底蕴。
于是当计算机引入到中国之初,国家技术监督局就设计了 GB 系列编码方案(GB 为 guo biao 的首字母缩写)。
GB 编码方案使用 2 个字节来表达一个汉字。同时为了兼容 ASCII 编码,规定各个字节的最高位(首位)必须为 1,从而避免了和最高位为 0 的 ASCII 字符集的冲突。
GB 系列字符集经历下面的几个发展过程:
| 编码名称 | 发布时间 | 字节数 | 汉字范围 |
|---|---|---|---|
| GB2312 | 1980 年 | 变字节(ASCII 1 字节,汉字 2 个字节) | 6763 个汉字 |
| GB13000 | 1993 年第一版 | 变字节(ASCII 1 字节,汉字 2 个字节) | 20902 个汉字 |
| GBK | Windows95 中 | 2 个字节 | 21886 个汉字和图形符号(含 GB2312,BIG5 中所有字符) |
| GB18030 | 2000 年第一版 | 变字节(ASCII 1 字节,汉字 2 个或 4 个字节) | 27484 个汉字 |
每一次迭代,支持的字符数量都会增加,而且每一次迭代都会保留之前版本支持的编码,所以做到了向上兼容。
全角与半角
因为汉字在显示器上的显示宽度要比英文字符的宽度要宽一倍,在一起排版显示时不太美观。所以 GB 编码不仅仅加入了汉字字符,而且包括了 ASCII 字符集中本来就有的数字、标点符号、字母等字符。这些被编入 GB 编码中的数字、英文标点符号、字母在显示器上的显示宽度比 ASCII 字符集中的宽度宽一倍,所以前者称为全角字符,后者称为半角字符。
ANSI
ANSI 与代码页
前面说到了世界各国针对 ASCII 的扩展方案(如欧洲的 ISO/IEC 8859,中国的 GB 系列等),这些 ASCII 扩展编码方案的特点是:他们都兼容 ASCII 编码,但他们彼此之间是不兼容的。微软将这些编码方案统称为 ANSI 编码。故 ANSI 并不是特指某一种编码方案,只有知道了在哪个国家,哪个语言环境下,才知道它具体表示哪个编码方案。
<原文出自: jiangxueqiao.com,请尊重原创>
在 Windows 操作系统上,默认使用 ANSI 来保存文件(但从 Windows 10 开始默认使用 UTF8 编码)。操作系统是如何知道 ANSI 到底应该表示哪种编码了,是 GBK 还是 ASCII,抑或还是 EUC-KR 了? Windows 通过一个叫”Code Page”(翻译为中文叫代码页)的东西来判断系统的默认编码。
简体中文操作系统的代码页默认是 936,即 ANSI 使用的是 GBK 编码。
GB18030 编码对应的 Windows 代码页为 CP54936。
可以使用命令chcp来查看和修改系统默认的代码页。
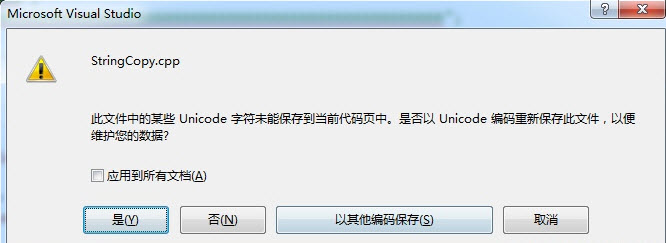
汉字“𤭢”(念 suì)只包含在 GB18030 中,GB2312、GB13000、GBK 中均不包含。默认情况下,Visual Studio 会使用 CP936(即 GBK)来保存代码文件,如果在代码文件中输入该汉字,Visual Studio 弹出如下提示要求用户选择代码页:
更改默认代码页
chcp 命令
可以使用chcp命令来更改默认代码页,如chcp 437将默认代码页更改为 437(美国)。
控制面板
在“控制面板”–>“区域和语言”–> “更改系统区域设置”中更改系统默认的代码页为“中文(简体,中国)”。
代码修改
也可以通过代码更改默认的代码页:
1 | char *setlocale( |
Unicode
Unicode 产生背景
各个国家使用不同的编码规则,虽然他们都是兼容 ASCII 的,但它们相互却是不兼容的。
试想法国人 Jack 写了一封名为”love_you.txt”的信,传给了他的德国朋友 Rose,Rose 想要在 windows 系统上打开这个文件,她需要知道德国使用的字符编码是 Latin-1,然后还要确保她的计算机上安装了该编码,才能顺利的打开这个文件。
如果上面这些还能忍受,那么随着网络的发展,你从互联网上获取的文件,你很有可能不知道它来自哪个国家,使用的哪种编码。这也就是 Email 刚诞生时常常出现乱码的原因,发信人和收信人使用的编码可能是不一样的。
于是The Unicode Standard(统一码标准)横空出世,它由 The Unicode Consortium 于 1991 年发布,我们习惯称它为 Unicode 字符集。
<原文出自: jiangxueqiao.com,请尊重原创>
Unicode 字符集和 ASCII 字符集一样,也只是一个字符集合,标记着字符和数字之间的映射关系,它不包含任何编码规则和方案。和 ASCII 不一样的是,Unicode 字符集支持的字符数量是没有限制的(具体可以参考 Unicode 规范)。
我们通常认为的 Unicode 字符固定占用 2 个字节的观点是错误的。如“𤭢”(念 suì)的 Unicode 码为
D852 DF62。
那么 Unicode 字符是怎样被编码成内存中的字节的呢?它是通过 UTF (Unicode Transformation Formats) 实现的,比较常见得有 UTF-8,UTF-16。
在 Windows 系统上汉字默认使用 CP936(即 GBK 编码),占 2 个字节。而大多数 Unicode 字符的 Unicode 码值也占 2 个字节,所以大多数人误以为汉字字符串在内存中的值就是 Unicode 值,这是错误的。
可以从 站长工具-Unicode 查询汉字的 Unicode 码值。
字符集与字符编码的区别
从 ASCII、GB2312、GBK、GB18030、Big5(繁体中文)、Latin-1 等采用的方案来看,它们都只是定义了单个字符与二进制数据的映射关系,一个字符在一个方案中只会存在一种表示方式,所以我们说 GB2312 是字符集还是字符编码方式都无所谓了。但是 Unicode 不一样,Unicode 作为一个字符集可以采用多种编码方式,如 UTF-8, UTF-16, UTF-32 等。所以自 Unicode 出现之后,字符集与字符编码需要明确区分开来。
UTF-16 编码的缺点
UTF-16 编码方式规定用两个或四个字节来表示所有的字符。对于 ASCII 字符保持不变,只是将原来的 7 位扩展到了 16 位,其高 9 位永远是 0。
如字符’A’:
1 | ASCII: 0100 0001 |
从上面可以看到,对于 ASCII 字符,UTF-16 的存储空间扩大了一倍,因此 UTF-16 并不是完全兼容 ASCII 字符集的。这对于那些 ASCII 字符集已经满足需求的西方国家来说完全是没必要的,而且 ASCII 字符经过 UTF-16 编码之后高字节始终是 0,还会导致很多 C 语言函数(如strcpy,strlen)将此字节视为字符串的结束符'\0',从而出现错误的计算结果。
而且,UTF-16 还存在大小端的问题,“𤭢”(念 suì)Unicode 码在大端系统上为D852 DF62,小端系统上为52D8 62DF。
因此,UTF-16 一开始推出的时候就遭到很多西方国家的抵制,影响了 Unicode 的推行。于是后来又设计了 UTF-8 编码方式,才解决了这些问题。
Unicode 字符集常用编码方式:UTF-8
UTF-8 概述
UTF-8 是互联网上使用最广泛的 Unicode 字符集编码方式。UTF-8 编码的最小单位由 8 位(1 个字节)组成,UTF-8 使用一个至四个字节来表示 Unicode 字符。另外,UTF-8 是完美兼容 ASCII 字符集的,这一点可以通过下面的 UTF-8 的编码规则得到证明。
UTF-8 编码规则
UTF-8 编码规则很简单:
(1)对于 ASCII(单字节字符)字符,采用和 ASCII 相同的编码方式,即只使用一个字节表示,且该字节第一位为 0.
(2)对于多字节(2~4 字节)字符,假设字节数为 n(1 < n <= 4),第一个字节:前 n 位都设为 1,第 n+1 位设为 0;后面的 n-1 个字节的前两位一律设为 10。所有字节中的没有提及的其他二进制位,全部为这个符号的 Unicode 码。按照这个规则,程序通过第一个字节中1的个数就可以知道当前字符编码所占的位数。
| Unicode 符号范围(十六进制) | UTF-8 编码方式(二进制) |
|---|---|
| 单字节:00000000-0000 007F | 0xxxxxxx |
| 双字节:00000080-0000 07FF | 110xxxxx 10xxxxxx |
| 三字节:00000800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 四字节:0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-8 BOM
BOM(byte order mark)从字面意义来看是标记字节顺序的。最早出现的原因是因为 UTF-16 和 UTF-32 编码采用 2 个或 4 个字节表示一个字符,面临大小端的问题。为了区分是使用的大端(Big Endian,简称 BE)还是小端(Little Endian,简称 LE),采用了在串的前面加入指定的字节加以区分,UTF-16 大端加入FE FF,小端加入FF FE. 比如, 字符串“ABC”的 UTF-16 编码为 00 41 00 42 00 43,对应的各种的字节序列如下:
| 序列 | 数据 |
|---|---|
| UTF-16BE (without BOM) | 00 41 00 42 00 43 |
| UTF-16LE (without BOM) | 41 00 42 00 43 00 |
| UTF-16BE (with BOM) | FE FF 00 41 00 42 00 43 |
| UTF-16LE (with BOM) | FF FE 41 00 42 00 43 00 |
因为 UTF-8 和 ASCII 扩展字符集都是单字节序列,二者不好区分,微软采用在 UTF-8 编码的字符串前也加入 BOM(3 个字节EF BB BF)来标记 UTF-8 编码的串。UTF-8 BOM 这一规范大多在 Windows 下被使用,在其他平台下用的很少使用,如 Linux 全部采用 UTF-8 编码,不存在需要区分的情况;HTTP 协议可以通过 Content-Type:text/html; charset=utf-8 来指定当前使用 UTF8 编码,也没有区分的需求。
编译器处理文件编码
Visual Studio 字符集
虽然使用 Visual Studio 创建的 C++工程可以在工程属性配置属性-->常规中配置字符集:使用Unicode字符集(默认)、使用多字节字符集。
如图: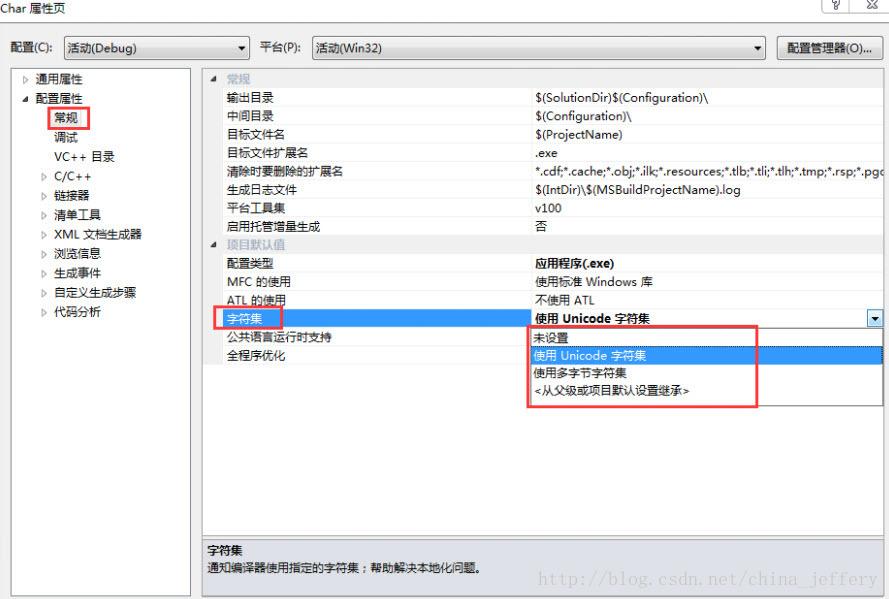
但这个设置项并不会对编译器处理字符编码产生直接的影响(注意这里的“直接”二字,第 3 节会说到),只会在工程属性配置属性-->C/C++-->预处理器加入相应的宏:
1 | 使用Unicode字符集 --> _UNICODE和UNICODE宏 |
这几个宏一般用来判断是使用 char 还是 wchar_t,在系统 API 中使用比较多,如 MessegeBox 通过判断是否定义了 UNICODE 宏来决定是使用 LPCSTR 还是 LPCWSTR(LPCSTR 即 const char*, LPCWSTR 即 const wchar_t*):
1 |
char 和 wchar_t
上面提到了,定义 API 时通过 UNICODE 宏来决定是使用 char 还是 wchar_t 类型,那么 char 和 wchar_t 有什么不同了?
char 和 wchar_t 是标准 C/C++字符类型,并不是 Windows 特有的。 char 固定占 1 个字节,wchar_t 固定占 2 个字节,从内存的角度来看,char、wchar_t 和其他数据类型一样,只是代表一段内存块,用来存储固定长度的二进制 0 或 1。 在编程时,我们一般习惯于将字符串储到 char 或 wchar_t 定义的内存空间中,将整形存储在 int 定义的内存空间中。
所以,用 char 还是 wchar_t 来存储字符,只是内存分配和数据存储上面的事情,它们本身也是与字符编码无直接关系的( 同样注意这里的“直接”二字,第 3 节会说到)。
编译器如何处理硬编码字符
MSVC 编译器编译源代码的步骤中,涉及编码处理的步骤主要有 2 个:
第 1 步:预处理
1.1) 读取源文件,判断源文件采用的字符编码类型。(这一步不会改变文件内容)
1 | 编译器判断源文件编码类型的步骤为: |
1.2) 将源文件内容转成源字符集(Source Character Set),默认为 UTF-8 编码。
第 2 步:链接
2.1) 将 1.2 中得到的 UTF-8 转为执行字符集(Execution Character Set):
- 对于宽字符串(wchar_t类型),执行字符集为 UTF-16 编码。
- 对于窄字符串(char类型),执行字符集为系统当前的代码页。

到现在我们彻底明白了 Visual Studio 字符集设置、char、wchar*t 是如何***间接_**影响到编译器对字符编码的处理了:
1 | Visual Studio字符集设置 |
在 Visual Studio 2010(含)之后,可以在代码中使用#pragma execution_character_set来设置执行字符集:
1 | // 执行字符集设置为utf8 |
也可以在Visual Studio项目属性中(“配置属性”>“C/C++”>“命令行”)中,通过/source-charset:utf-8 和 /execution-charset:utf-8 来分别设置源字符集和可执行字符集为utf-8。
实例分析
已知汉字“中”的各种编码如下:
1 | GBK D6 D0 |
函数DumpCharacterCode用于按字节打印内存中的数据:
1 | void DumpCharacterCode(const char* pChar, int iSize) { |
设置系统代码页的方法: “控制面板” –> “区域和语言” –> “管理” –> “非 Unicode 程序的语言” –> “更改系统区域设置”。
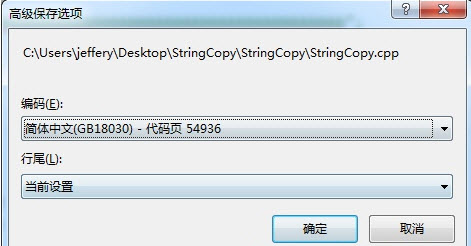
Visual Studio 保存文件到指定编码方法:“文件” –> “高级保存选项”。
测试编译器处理窄字符编码
测试代码如下:
1 | int _tmain(int argc, _TCHAR* argv[]) |
针对不同的系统代码页和源文件编码,打印出的汉字“中”的编码分别为:
| 测试用例 | 系统代码页 | 保存源文件编码 | 编译器判断文件采用的编码 | 源字符集(Source Character Set) | 执行字符集(Execution Character Set) | 打印输出 |
|---|---|---|---|---|---|---|
| 用例 1 | 简体中文 CP936 | 简体中文 CP936 | 简体中文 CP936 | UTF-8 | 简体中文 CP936 | D6 D0 |
| 用例 2 | 简体中文 CP936 | UTF-8 BOM | UTF-8 BOM | UTF-8 | 简体中文 CP936 | D6 D0 |
| 用例 3 | 简体中文 CP936 | UTF-8 | 简体中文 CP936 | UTF-8 | 简体中文 CP936 | 编译错误(C2146) |
| 用例 4 | 西欧 CP1252 | 简体中文 CP936 | 西欧 CP1252 | UTF-8 | 西欧 CP1252 | D6 D0 |
| 用例 5 | 西欧 CP1252 | UTF-8 BOM | UTF-8 BOM | UTF-8 | 西欧 CP1252 | 3F 00 |
表格中列 4~6 依次对应编译处理源文件的几个步骤。3F对应的 ASCII 字符为?,编译器遇到不能识别的字符时,就会用?来替代。 出现?的情况会伴随着编译警告C4566。
上面出现了 1 次3F(用例 5),导致乱码的原因是UTF-8 --> 西欧 CP1252. 西欧 CP1252也就是 ASCII 的扩展,不支持汉字,所以用3F替代。
用例 3 为什么会编译错误?
微软的编译器只能识别带 BOM 的 UTF-8,用例 3 的 UTF-8 没带 BOM,编译器会判定源文件编码为系统当前代码页 CP936。“中”的 UTF-8 编码为E4 B8 AD,列 5 执行从 CP936 到 UTF-8 转换之后变成了E6 B6 93 3F,列 6 再要将E6 B6 93 3F转换为 CP936 肯定是转换不回去的,相当于 UTF-8(1) –> UTF-8 (2),再将 UTF-8(2)转换回 CP936,这时肯定得到的字符不是原来的字符了。
用例 4 为什么输出的D6 D0,而不是3F?
对着用例 4 的各个顺序来看,源文件通过 CP936 保存着,但编译器通过 CP1252 来读取的,CP1252 就是 ASCII 扩展,单字节的,虽然此时显示为乱码,但各字节仍然是 D6 D0;然后将读取到的文件内容从 CP1252 转成 UTF-8 编码,转码后为 C3 96 C3 90;然后再将 UTF-8 编码转回为 CP1251,转码就又变成了 D6 D0。 但这个D6 D0在 CP1252 中是无法显示的,如果我们在用例 4 加入MessageBoxA(NULL, "中", "test", MB_OK); 会发现弹出的对话框中显示仍然是乱码。
可以使用下面的代码进行测试:
1 | int _tmain(int argc, _TCHAR* argv[]) |
测试编译器处理宽字符编码
测试代码如下:
1 | int _tmain(int argc, _TCHAR* argv[]) |
同样,针对不同的系统代码页和源文件编码,打印出的汉字“中”的编码分别为:
| 测试用例 | 系统代码页 | 保存源文件编码 | 编译器判断文件采用的编码 | 源字符集(Source Character Set) | 执行字符集(Execution Character Set) | 打印输出 |
|---|---|---|---|---|---|---|
| 用例 1 | 简体中文 CP936 | 简体中文 CP936 | 简体中文 CP936 | UTF-8 | UTF-16 | 2D 4E 00 00 |
| 用例 2 | 简体中文 CP936 | UTF-8 BOM | UTF-8 BOM | UTF-8 | UTF-16 | 2D 4E 00 00 |
| 用例 3 | 简体中文 CP936 | UTF-8 | 简体中文 CP936 | UTF-8 | UTF-16 | 编译错误(C2146) |
| 用例 4 | 西欧 CP1252 | 简体中文 CP936 | 西欧 CP1252 | UTF-8 | UTF-16 | D6 00 D0 00 大小端 |
| 用例 5 | 西欧 CP1252 | UTF-8 BOM | UTF-8 BOM | UTF-8 | UTF-16 | 2D 4E 00 00 |
使程序彻底告别乱码
要开发支持多语言,在任意语言(系统代码页)的 windows 环境下都正常编译,且运行起来没有乱码的程序,需要遵循如下原则:
- 代码文件采用 UTF-8 with BOM 编码。
- Visual Studio 字符集设置为 Unicode 字符集。
- 使用 wchar_t。
做到上面 3 步,你的代码被别人从 github 上 clone 下来编译,不会因为你代码中含有中文等字符,产生类似error C2015这样的编译错误,更不会产生乱码。
本文介绍的方法只用来解决硬编码字符乱码的问题,至于数据传输中的乱码,需要统一字符编码来解决。
MySQL字符编码
MySQL 字符集和校对规则
MySQL 的字符集是用来定义 MySQL 存储字符串的方式,校对规则(有的软件叫排序规则)则是用来定义了比较字符串的方式。
字符集和校对规则是一对多的关系。每种字符集都有一个默认校对规则。
查看数据库支持的字符集:
1 | # 方法1: |
查看数据库支持的校对规则:
1 | # 方法1: |
MySQL 各个级别字符集
MySQL 可以对如下字符集进行设置:
- 服务器级字符集(CHARACTER_SET_SERVER)
- 数据库级字符集(CHARACTER_SET_DATABASE)
- 表级字符集
- 字段级字符集
- 连接字符集(CHARACTER_SET_CONNECTION),客户端连接数据库所用的字符集。
- 结果字符集(CHARACTER_SET_RESULTS),存储查询结果(含错误信息)所用的字符集。
- 客户端字符集(CHARACTER_SET_CLIENT),客户端发送给 MySQL 服务器的查询语句字符集。
- 系统字符集(CHARACTER_SET_SYSTEM),用于存储我们新建的或自带的数据库的表、列的名称,默认是 UTF-8。
服务器级、数据库级、表级、字段级 这 4 个字符集设置影响到数据库中存储数据的编码。 这 4 个级别的字符集继承关系为:服务器级 --> 数据库级 --> 表级 --> 字段级, 从左到右,一级继承一级,和 C++、Java 中的类的继承类似,如果某一级未显式的指定字符集,那么将继承上一级的字符集设置。
服务器级别字符集设置
服务器级别的字符集可以从下面几个地方指定,从上到下优先级依次增加:
- 编译 MySQL 时指定的字符集
- my.cnf 配置文件设置 character-set-server
- mysqld 服务启动命令行中指定字符集
影响数据存储的字符集之间的关系: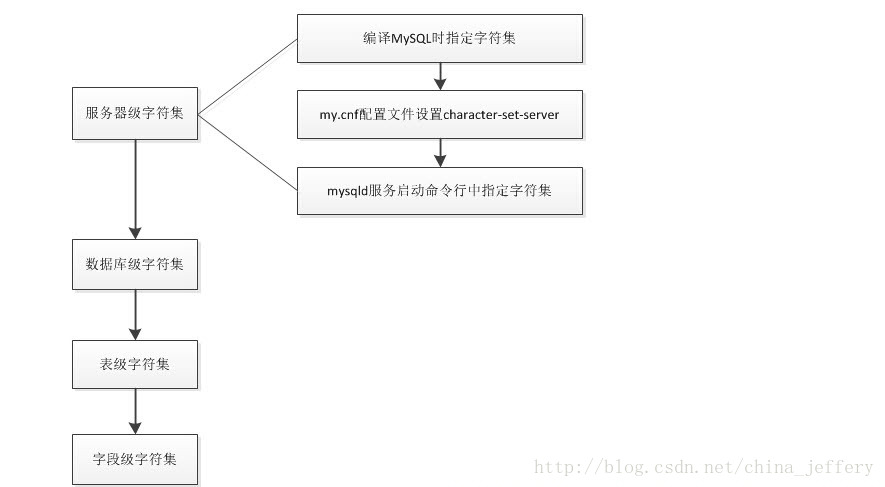
查看当前数据库的字符集设置:
1 | # 方法1: |
utf8 与 utf8mb4 区别
UTF-8 是多字节编码方案,采用 1~4 个字节来存储一个字符,但在 MySQL 设计之初,一个字符最多采用 3 个字节的就可以存储,所以 Mysql 的设计者将 MySQL 中的 UTF-8 字符集(UTF-8 其实不是字符集,是字符编码方案,但在 MySQL 中一直这么叫)设计成了最大长度只能为 3. 如图:
但随着 Unicode 字符集的扩张,出现了需要 4 个字节才能存储的字符,如果这时仍然使用 utf-8(指 mysql 中的 3 字节 utf-8)来存储这些字符就会出现错误,
如执行INSERT INTO member(memberName)VALUES('𤭢')报错如下:
1 | Warning Code : 1366 |
于是 MySQL 后来新增了 utf8mb4 字符集,最大长度为 4,兼容之前的 utf8,但为了之前的数据库不报错,仍然保留了之前的 utf8 字符集。 所以 MySQL 中的 UTF-8 字符集是伪 UTF-8,现在需要使用 utf8mb4。
MySQL完全避免乱码
要完全避免字符乱码,最简单也是最好的方法就是将各个字符集保持一致,可以都设置为 utf8mb4。
Mysql 数据存储所涉及到的 4 个字符集的设置可以使用第二节的方法进行设置,客户端字符集、连接字符集,结果字符集关系到数据显示的正确性,可以使用如下语句统一设置为 utf8mb4,但这个设置只针对当前连接有效:
1 | set names utf8mb4; |
编程开发中,一般使用 MySQL API 进行数据连接、查询等操作,可以使用mysql_set_character_set对每个连接进行设置,这个 API 会将客户端字符集、连接字符集,结果字符集都设置为指定字符集,代码大致如下:
1 | MYSQL* pMysql = NULL; |
Qt字符编码
我们以“测试字符串-보고싶다-Test String.”这个字符串来进行讲解,它包含了英文、中文和韩文。
因为我使用 Qt 的方式是Visual Studio + Qt库的形式,所以本文以 MSVC 编译器为例来进行说明,但这种方式的原理也适用于其他编译器。
QString 中使用 QChar 来存储每一个字符,QChar 是 short 类型,占 2 个字节,默认按 Unicode 编码存储。
首先,为了保证写到代码文件中的测试字符串能被 MSVC 编译器理解,我们需要将源文件保存为Utf8-带签名的格式。
解决 Qt 程序乱码问题的关键在于理解QString中存储字符的编码格式。
QString 中存储的字符串的编码格式就是“编译器执行字符集编码格式”。 这一句话很关键。
在 MSVC 中我们可以使用#pragma execution_character_set("utf-8")来指定该源文件的执行字符集编码格式为 UTF8 格式,这样 QString 中存储的字符串格式就是 utf8 编码了。
下面是完整的测试用例:
1 | void Demo01::qStringUseCase() { |
QString::toLocal8Bit
QString 有一个名为toLocal8Bit的方法,网上很多介绍如何解决乱码的文章都会提到这个函数。关于这个函数官方的介绍如下:
1 | Returns the local 8-bit representation of the string as a QByteArray. The returned byte array is undefined if the string contains characters not supported by the local 8-bit encoding. |
简而言之,toLocal8Bit 函数将字符串转换为的 ANSI 编码,ANSI 是和具体的代码页相关联的(在 Windows 中文环境下默认代码页为 936)。Qt 不是根据系统代码页来做判断的,而是通过QTextCodec来做判断的,所以文档中会提到这个函数需要结合QTextCodec::codecForLocale()来使用,toLocal8Bit根据对应的QTextCodec来做相应的转换。
Qt程序告别乱码
所以要想在使用 Qt 时,避免遇到中文乱码问题,只需要在预编译头文件中加入(对于不使用预编译头的项目可以在.cpp文件中添加):
1 |
同时由于部分韩文、日文等字符不在 Visual Studio 默认的中文 GB2312 编码中,所以如果遇到 Visual Studio 提示“此文件的某些 Unicode 字符未能保存到当前代码页中”时,这时应该选择”Utf8-带签名“格式来保存。
综上所述,源文件保存为Utf8-带签名,且设置编译器执行字符集编码为UTF8(如#pragma execution_character_set("utf-8"))就可以解决所有乱码问题。
文章图片带有“CSDN”水印的说明:
由于该文章和图片最初发表在我的CSDN 博客中,因此图片被 CSDN 自动添加了水印。