Windows内存体系(4)--内存对齐
为什么要内存对齐
平台原因
不是所有的CPU都能访问任意地址上的任意数据的,有些CPU只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
性能原因
尽管内存是以字节为单位,但是大部分处理器并不是按字节块来存取内存的,它一般会以双字节、四字节、8字节、16字节甚至32字节为单位来存取内存,我们将上述这些存取单位称为内存存取粒度。
如果数据存储时是按照内存存取粒度对齐的,那么处理器就可以在一个内存访问周期内完成数据的读取;反之,如果数据没有对齐,可能需要多个内存访问周期才能读取完整的数据。
内存对齐规则
对齐系数
在 C/C++ 中,编译器会在结构体(联合体、类)成员之间插入填充字节,以确保每个成员都按照特定的对齐要求进行存储,以提高内存访问效率。
每个编译器都有自己的默认“对齐系数”(也叫对齐模数)。GCC默认对齐系数为4,MSVC 32位默认对齐系数为8,MSVC 64位默认对齐系数位16。
我们可以在代码中通过预编译命令#pragma pack(n)来指定对齐系数,n 可以为 (1, 2, 4, 8, 16)中的任意一个。
下面是 #pragma pack 命令的基本用法:
1 |
对齐规则
假设在一个结构体(联合体、类)中,最大数据类型长度为 m,编译器对齐系数是 n,则将 min(m, n) 称做对齐单位,也叫有效对齐值,这里记为 s。
对齐分为成员对齐和结构体(联合体、类)整体对齐。
- 成员对齐规则:第一个成员相对于结构体首地址的偏移量始终为 0,以后每个成员(数据类型长度记为 k)相对于结构体首地址的偏移量都为
min(k, s)的整数倍。 - 整体对齐:结构体的总大小必须是有效对齐值 s 的整数倍。
从内存对齐的规则可以看出:`
- 除第一个成员外,每个成员的偏移量:
min(k, min(m, n)) - 如果设置的对齐系数 n 大于类中最大数据类型长度 m 时,则该设置实际是不起作用的。
- 当对齐系数 n == 1 时,整个结构体的大小为所有成员长度之和。
结构体内存对齐示例
<原文出自: jiangxueqiao.com,请尊重原创>
在 64 位系统上编译下面的测试程序,已知在 64 位系统上各类型占用字节数如下:
1 | char 1字节 |
示例代码如下:
1 |
|
按照第二节所讲的内存对齐规则,分析如下:
因为结构体中最大的数据成员长度为 int(即 4 字节),而且#pragma pack(8)指定的对齐系数为 8 ,所以有效对齐值 s 为 min(4, 8) = 4。
下图是结构体 A 按照 4 字节对齐的内存布局,内存填充在 s4 后面,而不是填充在 c 后面。另外,图中的内存地址按照从下向上的方向增长的。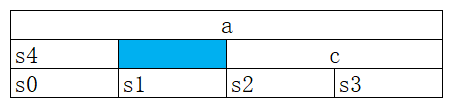
从图我们很容易知道sizeof(A) = 12.